Ist eigentlich schon jemandem aufgefallen, dass Google, neben dem gefürchteten Panda 4.0 noch weitere Neuerungen auf den Weg geschickt hat? Nein, ich meine jetzt nicht dieses komische Google Car, welches aussieht wie eine Mischung aus Fiat 500, SMART und Einkaufswagen für Kinder.

Nein, das selbstfahrende Dingens meinte ich nicht, sondern die Neuerung in den Webmaster-Tools von Google. Ich könnte schwören, vor 2 Tagen war die Funktion noch nicht vorhanden.
Abruf wie durch Google bekommt neues Feature
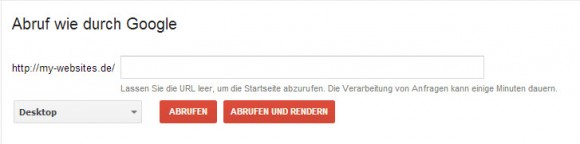
Wer seine Seite mit dem „Abruf wie durch Google“ hin und wieder checkt und / oder eine neue Seite schneller in den Index quetschen will, der kennt sicherlich diesen praktischen Menüpunkt innerhalb der Webmaster-Tools schon. Ich habe allerdings heute Nacht nicht schlecht gestaunt, als ich den „Abrufen und Rendern“ Button entdeckte.
Ok, man(i) ist ja von Natur aus neugierig und wenn es schon mal was Neues für den Xovilichter Wettbewerb geplagten Webmaster gibt, dann drückt man eben mal das neue Knöpfchen und schaut, was Google dann so ausspuckt.
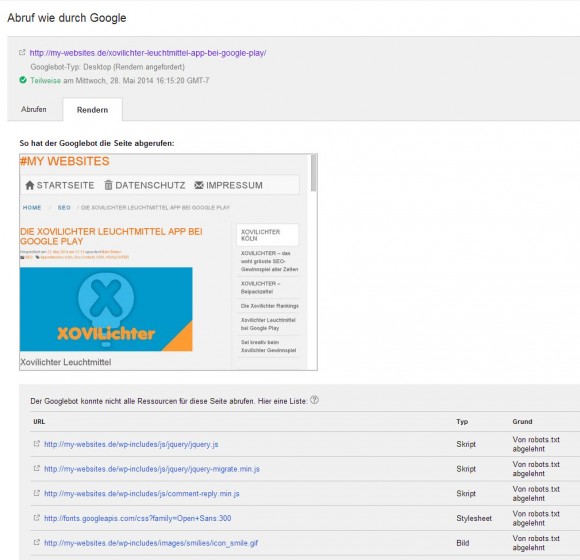
Google ruft die eigene Webseite auf und versucht die Seite besser zu lesen und bindet hierfür auch alle Scripts mit ein. Blöd nur, wenn man per robots.txt vorher dem Google Bot verboten hat, bestimmte Verzeichnisse zu betreten. Schon wird die Seite nicht mehr „richtig“ dargestellt und unten erscheinen diverse „Fehlermeldungen“.
In order to render the page, Googlebot will try to find all the external files involved, and fetch them as well. Those files frequently include images, CSS and JavaScript files, as well as other files that might be indirectly embedded through the CSS or JavaScript. These are then used to render a preview image that shows Googlebot’s view of the page.
Ich also erstmal die robots.txt abgeändert, inwieweit das nun gut oder schlecht sein kann wird sich noch zeigen, und die Seite erneut in das Test-Tool getackert und auf geht’s Google „abrufen und rendern“.
Und siehe da, die Anzeige ist fast fehlerfrei, aber nur fast, denn ausgerechnet Google selbst blockt wohl seine eigenen Seiten und bringt mir hier den einzigen Fehler. Das macht Google aber fein!
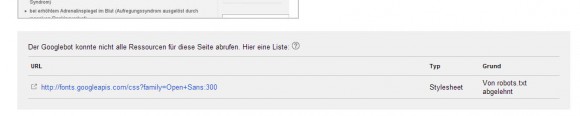
Naja, wollen wir mal nicht so sein, im offiziellen Googlewebmastercentral Blog wird ja auch erklärt, dass unbedeutende Sachen wie „Social Media Buttons“, „Schriftarten“ und „Webanalytics Skripte“ auch weiterhin per disallow in der robots.txt ausgesperrt werden können. Blöd nur, dass Google sich ja hier wohl selbst aussperrt.
We recommend making sure Googlebot can access any embedded resource that meaningfully contributes to your site’s visible content, or to its layout. That will make Fetch as Google easier for you to use, and will make it possible for Googlebot to find and index that content as well. Some types of content – such as social media buttons, fonts or website-analytics scripts – tend not to meaningfully contribute to the visible content or layout, and can be left disallowed from crawling. For more information, please see our previous blog post on how Google is working to understand the web better.
Ich bin mir noch nicht ganz so schlüssig, was ich von dieser Neuerung halten soll. Bringt mir diese Neuerung wirklich etwas, kann ich damit meine SERPs verbessern, verbessert Google damit das Verständnis für die Seiten und / oder kann ich damit gar am Schluss noch ein paar SEO Features einbauen?